

Go back to Blog
Introducing training samples – machine learning meets positive controls to boost confidence in your PCR data

Interpreting rare target signals in qPCR and dPCR often involves a degree of uncertainty. Is that low signal a true positive or only assay noise? Analysts rely on thresholding, visual inspection, or statistical cutoffs — approaches that are inconsistent, especially close to qPCR and dPCR limits of detection.
Countable PCR offers a smarter path forward: a built-in, optional machine learning step that adapts to each run using a positive control called a training sample. It’s a simple addition when needed, and it enables more confident rare target detection without changing core assay design. And it’s especially useful for applications that demand high specificity.
Training samples are well-defined control reactions that help Countable PCR learn what a true signal looks like under the exact conditions of a given run. When included, they allow the software to calibrate its classification model dynamically, using actual reaction data rather than fixed thresholds.
.webp)
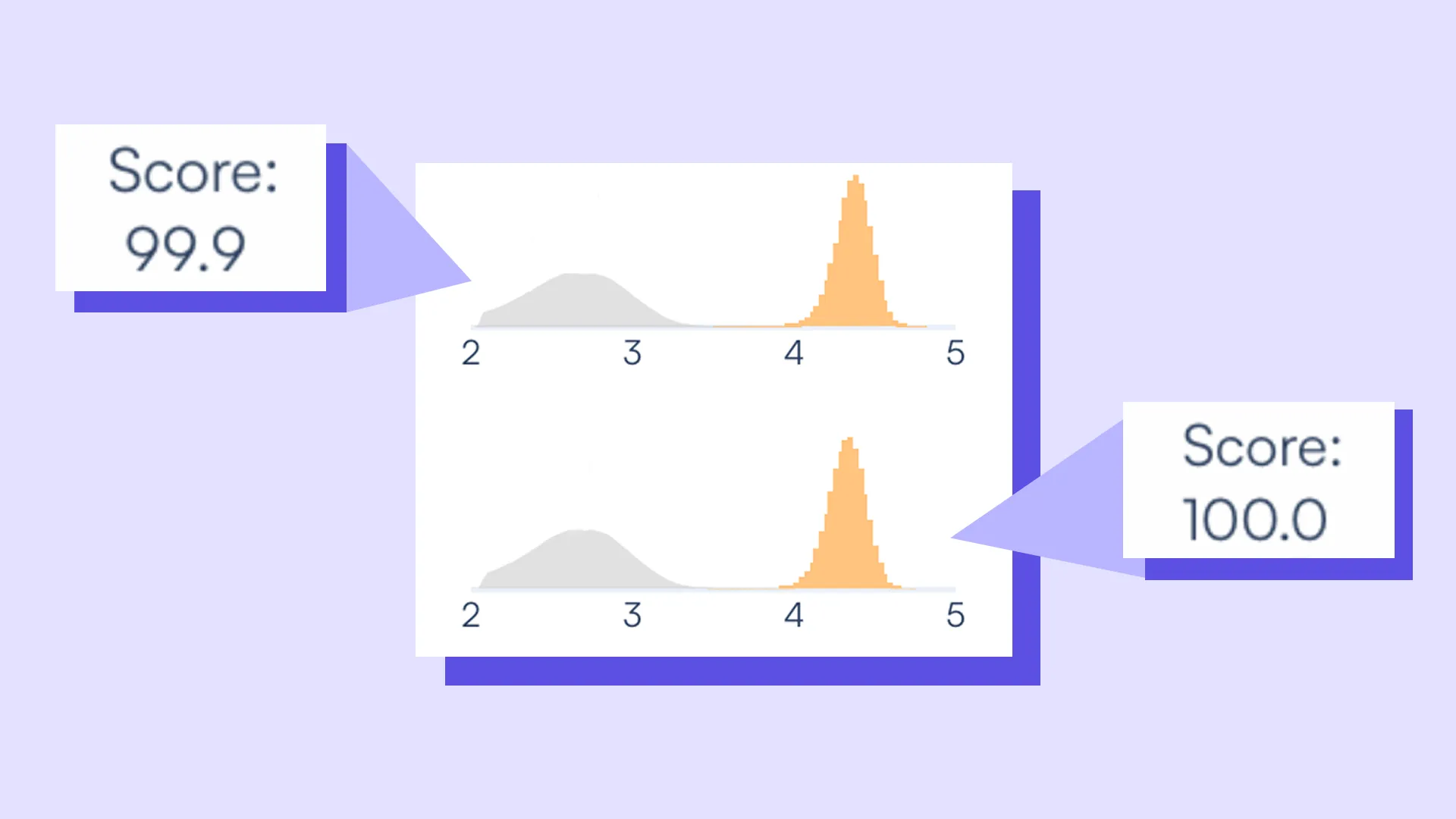
This approach is especially useful when distinguishing low-level targets from background noise, such as in rare variant detection, microbial surveillance, or minimal residual disease monitoring. In these contexts, small differences matter, and subjective interpretation results in overcalling or missed detections.
By feeding the model real examples of “known positives,” the training sample workflow brings greater precision and reproducibility, without requiring users to manually adjust analysis parameters.
Not necessarily. Countable PCR is designed to run without training samples and will still deliver accurate quantification across a broad dynamic range. For many common assays — especially those with strong signal separation or high-abundance targets — the built-in model performs great out of the box.
Training samples are best reserved for cases where maximum specificity is essential, or when working in high-background, low-abundance scenarios where traditional methods fall short. They’re simply a way to fine-tune the system when stakes are high.
When used, a training sample should closely mimic the test sample, but with known inputs. This gives the algorithm a clear reference for distinguishing true positives from assay noise.
Best practices include:
For example, a variant detection assay might include gDNA at 50% VAF or synthetic SNVs in a cfDNA background. A microbial assay would use synthetic target sequences spiked into fragmented host DNA. The closer the training sample mirrors the experimental sample (minus the uncertainty), the better the model performs.
Countable PCR offers rare target detection that’s easy and adaptable. The optional training sample workflow adds run-specific intelligence when needed — improving clarity and boosting confidence in your results.

Single-molecule precision. Make it count
.webp)
